大致上了解 lexical analyzer 做了什麼之後,我們可以再更進一步看細節:
- 字串怎麼讀?
- 字串怎麼切?
- token class 怎麼定義?
字串怎麼讀?
當專案很大,程式碼很多時,讀取速度當然就愈慢 。因此,讀程式碼時就不是一個字元一個字元慢慢讀了,而是一次抓取多個字元放進緩存的 buffer 中。畢竟和 disk 拿取資料, 系統呼叫的成本是很高的呢!於是每次拿取的資料的單位就與 disk block 大小一致,如果檔案沒那麼大的話,就會在最後面加一個特殊的結尾字符,一般稱之為 eof (end of file)。所以當遇到 eof 時,就知道要更新 buffer,拿下一段的程式碼了。
字串怎麼切?
有了 input stream 後,要切。但怎麼知道這一刀要下在哪裡?怎麼記住每一段的範圍呢?龍書中提到使用兩個標記標住起點與終點:lexemeBegin, forward。
想法很簡單:
由 forward 不斷前進,找到符合規則的 token 後就記錄下來,更新 lexemeBegin,然後再重複直到結束。
token class 怎麼定義?
這個部份就是利用 lex 或 bison 實做 scanner 的重頭戲。如何訂一條規則,描述出這個 token 的 pattern 呢?這就需要 RE (regular expression) 出場了!所謂的 regular expression 其實就是透過定義一些符號試圖精簡的表示以個語句的規則,這個的應用場合非常廣泛,如在很多「搜尋」的場景都能夠使用 RE 過濾出目標。
詳細的 RE 語法可以參照 正規表達式 Regular Expression
在龍書中還提到了在建構 lexical analyzer 時,會先把 regular expression 轉換成狀態轉移圖表示 (transition diagram),為的是能建構一連串的判斷動作,如圖:
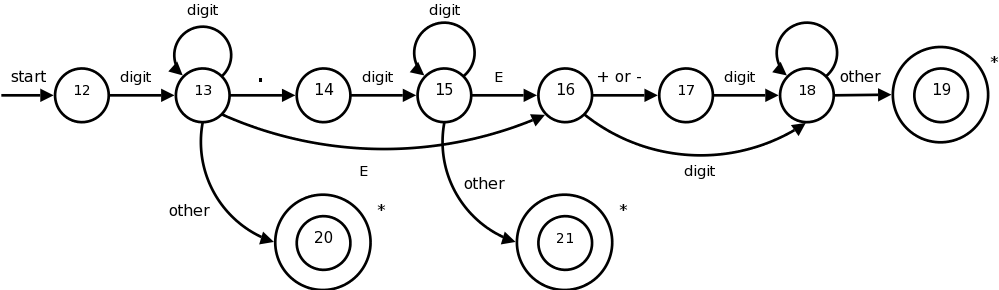
每一個原圈代表一個狀態,當走到雙圈時就代表最終狀態且是被接受的!而每一條箭頭稱為 edge,代表在狀態 a 且遇到 edge 上的字元時前進到箭頭指向的狀態 b。例如:在 state13 時,遇到 E 即前進到 state16。
也就是說每一個 token 都會轉成不同的 transition diagram,我們便可以把這張圖轉換成以 switch case 的程式碼,如下:
1 | TOKEN getRelop() // TOKEN has two components |
沒走到雙圈的最終狀態 == fail ?
這答案是不夠全面的,沒有走到雙圈並不代表這個字串是有誤,而是他不屬於這一個 token class 的。因此會繼續以走下一個 token class 的 transition diagram,直到最終狀態。如果某個字串它能多個匹配不同 token class 的話,便會歸類給最先走成功的 token class。
真正的 fail 是在於當所有 transition diagram 都走完且沒有任一匹配的時候,這時候 lexer 就會直接噴錯囉!