當專案很大,程式碼很多時,讀取速度當然就愈慢 。因此,讀程式碼時就不是一個字元一個字元慢慢讀了,而是一次抓取多個字元放進緩存的 buffer 中。畢竟和 disk 拿取資料, 系統呼叫的成本是很高的呢!於是每次拿取的資料的單位就與 disk block 大小一致,如果檔案沒那麼大的話,就會在最後面加一個特殊的結尾字符,一般稱之為 eof (end of file)。
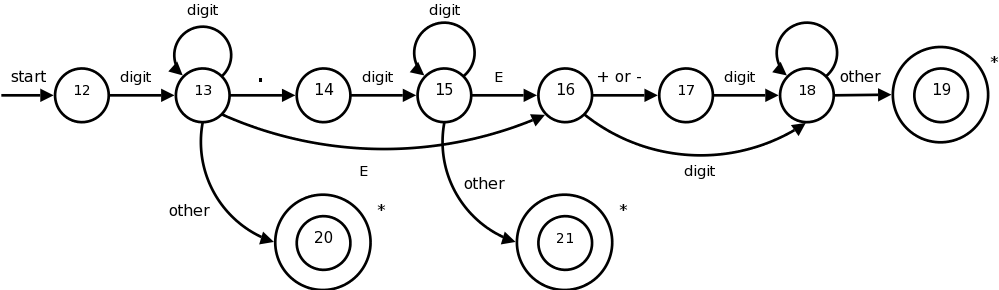
每一個原圈代表一個狀態,當走到雙圈時就代表最終狀態且是被接受的!而每一條箭頭稱為 edge,代表在狀態 a 且遇到 edge 上的字元時前進到箭頭指向的狀態 b。例如:在 state13 時,遇到 E 即前進到 state16。
也就是說每一個 token 都會轉成不同的 transition diagram,我們便可以把這張圖轉換成以 switch case 的程式碼,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
TOKEN getRelop() // TOKEN has two components TOKEN retToken = new(RELOP); // First component set here while (true) switch(state) case 0: c = nextChar(); if (c == '<') state = 1; else if (c == '=') state = 5; else if (c == '>') state = 6; else fail(); break; case 1: ... ... case 8: retract(); // an accepting state with a star retToken.attribute = GT; // second component return(retToken);
沒走到雙圈的最終狀態 == fail ?
這答案是不夠全面的,沒有走到雙圈並不代表這個字串是有誤,而是他不屬於這一個 token class 的。
因此會繼續以走下一個 token class 的 transition diagram,直到最終狀態。如果某個字串它能多個匹配不同 token class 的話,便會歸類給最先走成功的 token class。
其實編譯器的角色套用在現實生活中能夠特別清楚的解釋他的角色及功用 – 翻譯人員。不論是即時口譯還是各節目或動畫的專業字幕組都是,反正只要始能把 A 語言流暢的翻成 B 語言的都算。但翻譯的工作並不是那麼簡單,需要理解某語言的生字、語法才能夠進行,當然更專業的人員還能夠使用精簡的句子傳達意境,甚至即使他文法錯了,翻譯大大也能理解並精準的譯出正確的意思。總之,翻譯其實不僅僅是「翻譯」,還要再經過「編輯」,這也就是 “compile” 「編譯」的意思。